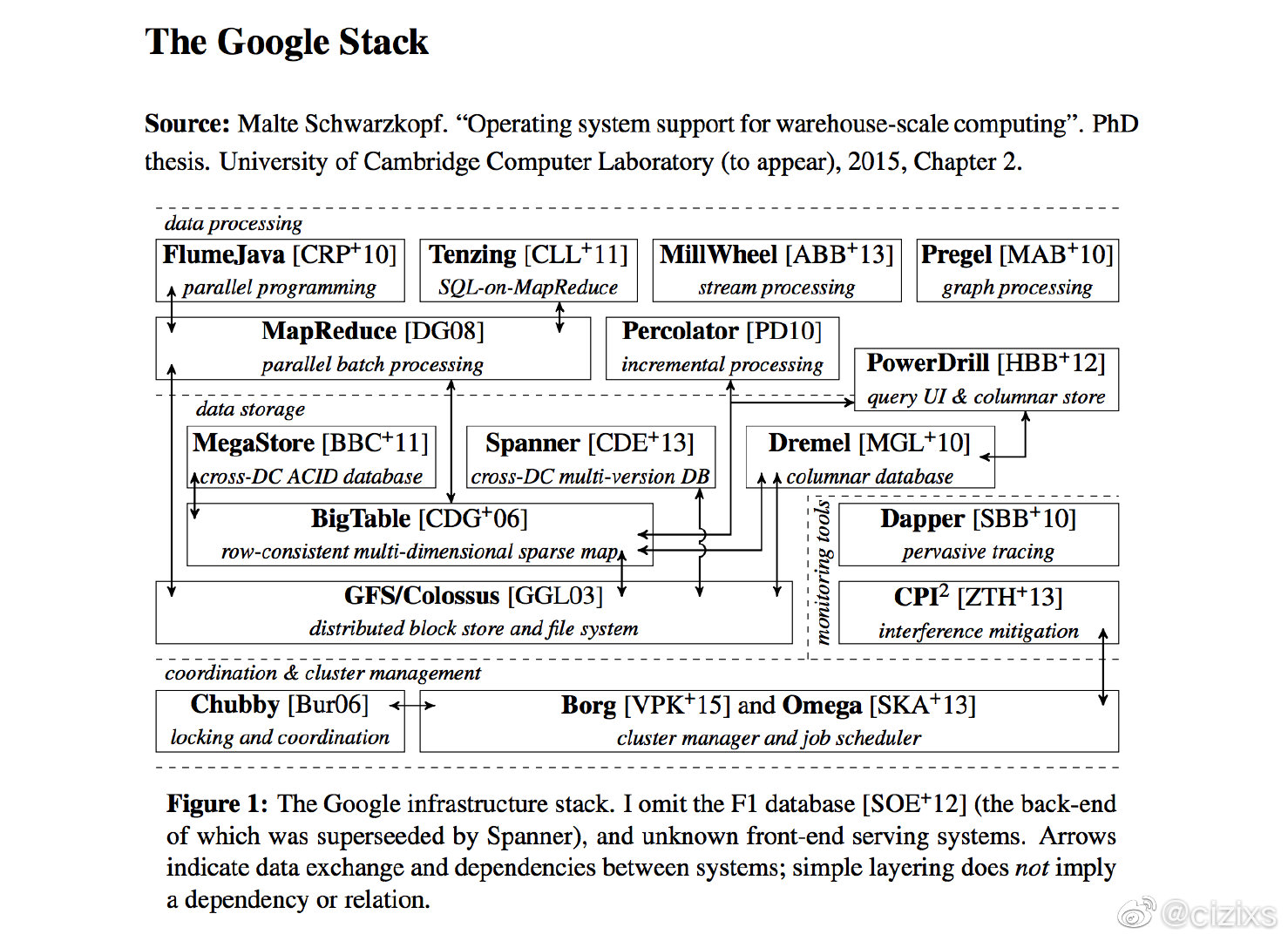
用户1340774522 转发了 @cizixs 的微博:一篇 PhD 论文中绘制的 Google 核心组件技术栈的示意图,这些内容是从各个论文和公开资料中整理的,因此不一定完整和最新,但是能让我们一窥 Google 的基础设施技术。
我们都知道 Google 的基础设施非常强,这个图片能够作为强有力的作证。我来试图简单介绍下各个组件的功能,以及对整个业界的影响:
- Borg and Omega:Borg 是 Google 内部的容器管理平台,所有的应用都会直接运行在这个平台上,现在如日中天的 kubernetes 就是 Borg 的开源版本,Omega 是 Borg 的后继者。Borg 以及 kubernetes 的出现让业界都能够轻松地使用容器技术管理整个基础设施,DCOS 和 cloud-native 的概念越来越深入人心
- Chubby:Chubby 是分布式锁和协调中心,分布式系统非常基础和核心的组件,分布式系统最常用的 pattern,比如:服务发现、分布式锁、leader election、分布式配置中心都可以基于 Chubby 实现。Chubby 的出现影响了开源的 etcd、zookeeper 和 consul 系统。 Chubby 让分布式系统开发变得平民化
- GFS/Colossus:GFS 是 Google File System 的缩写,是集群规模的分布式、可扩展的文件存储系统,GFS 和 BigTable、MapReduce 并成为三驾马车,直接启发雅虎创建了 Hadoop 大数据生态系统,开启的大数据浪潮,直到今天还在继续。GFS 的出现让存储一体化,强大的分布式和容错能力让应用可以像使用单机文件系统那样使用分布式的文件存储,极大降低了分布式存储开发的门槛。Colossus 是 Google 内部 GFS 的替代产品,可以看做 GFS 2.0
- MapReduce:作为三驾马车之一,MapReduce 是一个计算框架,通过编程中的 divide-and-conquer 思想,把计算分解成 Map 和 Reduce 两个过程,使用分布式存储 GFS 作为中间衔接,让海量数据的快速计算编程可能。开源界对标的就是 Hadoop MapReduce 框架
- BigTable:A Bigtable is a sparse, distributed, persistent multi-dimensional sorted map,简单来说就是一个分布式的数据库,当然它最初的设计没有延续关系数据库模型,而是使用稀疏的多维哈希来表示,可以非常灵活地存储海量数据。如果说 GFS 让我们知道分布式数据库应该是什么样子的话,BigTable 则是分布式数据库最初的模样,HBase 就是 BigTable 的开源实现
- Spanner:虽然已经有了分布式数据库,但是 BigTable 有两个问题:一个是不支持跨行事务,这对于很多高可靠性的业务来说编程会非常困难;另外就是接口模型不是我们熟悉的 SQL,很多应用无法直接使用,因此后面诞生了 Spanner 这个系统,Spanner 可以看成 MySQL 的分布式版本,可以无限水平扩展,能够自动 sharding,并且支持事务,这些特性让传统的应用可以把 Spanner 当做一个无限大的 MySQL 来用。Spanner 是 NewSQL 的旗杆,CockroachDB 和 TiDB 都是模仿 Spanner 而出现的
- CPI:CPI 应该是 Cycles Per Instruction,只是一个衡量应用的运行情况的指标,在 Borg 的论文中提到使用这个参数对应用进行调优
- Dapper:Dapper 是一个分布式系统链路追踪组件,Google 2010 年的一篇论文介绍了它的设计。提出来的 Trace 和 Span 概念已经深入人心,目前开源的 Zipkin 和 Jaeger 都受到了它的影响。从技术深度和含量上来说,Dapper 并不复杂,但是对于越来越复杂的分布式系统的调试来说却非常有用
- Dremel:Dremel 和 Pregel、Caffeine 并称为新时代三驾马车,Dremel 负责实时的交互式查询分析,用户可以使用 SQL 查询 PB 级别的数据,结果能够在秒级别返回。Google 提供的 BigQuery 就是基于 Dremel 的。根据公开数据,Dremel 能够在 10s 级别扫描 350 亿行的数据,性能非常快。Dremel 采用列式存储,以及树形的结构。 Dremel 的缺点是不支持更新操作,因为列式存储会让更新效率非常低。开源社区对标的产品是 Presto
- PowerDrill:和 Dremel 定位类似,也是交互式的查询分析,但是主要定位是分析少量的大数据集,提供更好的分析性能。PowerDrill 数据保存在内存,并且对数据做了分区,因此检索时可以快速跳过不需要的区间。Dremel 和 PowerDrill 对应的开源产品是 Apache Druid
- Percolator:大数据事务处理的解决方案,可以在同一个事务中支持成千上万条数据的更新。Percolator 基于 BigTable,在支持海量数据、随机读写的基础上,加上了对事务的支持。在性能方面,Percolator 偏重于吞吐,在处理时效性方面不是那么好
- Tenzing:SQL on MapReduce 系统,在 MapReduce 系统上面提供 SQL 接口方便用户使用。因为 SQL 是数据分析的标准接口,因此在使用上会比直接编写 MapReduce 代码方便而且兼容性更好。 对标的开源系统是 Apache Hive。
- MillWheel:大规模分布式的流处理系统,随着互联网业务中对实时性的要求越来越高,流处理系统变得越来越重要。MillWheel 的论文在 13 年公开,如今流处理领域在开源已经竞争地如火如荼,Spark 和 Flink 是首选,但是 Storm、Kafka、Pulsar 也是不错的产品
- Pregel:分布式的网络和图算法,可以用于图遍历、最短路径,PageRank 也会用到图算法。对标的开源产品是 Apache Giraph
总结:
Google 的整个架构设计整体采用层级的方式,某些系统成熟稳定之后作为基础,在上层构架其他的服务,比如 BigTable 底层会用到 GFS,很多系统都用到了 Chubby,这种构建方式可以在后期实现快速的新产品开发迭代。
另外能看到的是,Google 内部系统强在对大规模数据的存储、分析和处理,因此在数据库、分布式计算方面的框架非常多,这是为了解决它们实际遇到的问题。这也是 Google 一贯的风格,非常强调实用性,技术非常有前瞻性。
即使是 Google,内部系统的设计也会有大的重构和替代,比如 GFS -> Colossus,Borg -> Omega 等,这是一个大的系统架构演进正常的事情:要么在原来的系统上进行大的重构,要么就是用新的经验重写。而大型系统往往因为代码复杂,设计之初的缺陷改动难度大,上面运行业务迁移和兼容困难,全部重写并不是一个不能接受的选项(尤其是对于 Google 这种有足够技术能力的公司来说)。
Google 在大数据处理方面还是要领先业务不少的,但大家也都知道 Google 开创的大数据领域自己并没有得到什么好处,因此这几年 Google 的模式有了很大的变化:一方面使用 CNCF 和开源来吸引社区用户,一方面把自己的成熟技术直接在 GCE 中做成产品对外开放,把内部技术充分利益化。
对于其他公司来说,没有必要完全复制 Google 的技术栈。架构是演进出来的,公司不同发展阶段应该采用不同的技术架构,另外不同公司遇到的问题和 Google 也会不同,选择适合自己的架构才是正确的路。
我们都知道 Google 的基础设施非常强,这个图片能够作为强有力的作证。我来试图简单介绍下各个组件的功能,以及对整个业界的影响:
- Borg and Omega:Borg 是 Google 内部的容器管理平台,所有的应用都会直接运行在这个平台上,现在如日中天的 kubernetes 就是 Borg 的开源版本,Omega 是 Borg 的后继者。Borg 以及 kubernetes 的出现让业界都能够轻松地使用容器技术管理整个基础设施,DCOS 和 cloud-native 的概念越来越深入人心
- Chubby:Chubby 是分布式锁和协调中心,分布式系统非常基础和核心的组件,分布式系统最常用的 pattern,比如:服务发现、分布式锁、leader election、分布式配置中心都可以基于 Chubby 实现。Chubby 的出现影响了开源的 etcd、zookeeper 和 consul 系统。 Chubby 让分布式系统开发变得平民化
- GFS/Colossus:GFS 是 Google File System 的缩写,是集群规模的分布式、可扩展的文件存储系统,GFS 和 BigTable、MapReduce 并成为三驾马车,直接启发雅虎创建了 Hadoop 大数据生态系统,开启的大数据浪潮,直到今天还在继续。GFS 的出现让存储一体化,强大的分布式和容错能力让应用可以像使用单机文件系统那样使用分布式的文件存储,极大降低了分布式存储开发的门槛。Colossus 是 Google 内部 GFS 的替代产品,可以看做 GFS 2.0
- MapReduce:作为三驾马车之一,MapReduce 是一个计算框架,通过编程中的 divide-and-conquer 思想,把计算分解成 Map 和 Reduce 两个过程,使用分布式存储 GFS 作为中间衔接,让海量数据的快速计算编程可能。开源界对标的就是 Hadoop MapReduce 框架
- BigTable:A Bigtable is a sparse, distributed, persistent multi-dimensional sorted map,简单来说就是一个分布式的数据库,当然它最初的设计没有延续关系数据库模型,而是使用稀疏的多维哈希来表示,可以非常灵活地存储海量数据。如果说 GFS 让我们知道分布式数据库应该是什么样子的话,BigTable 则是分布式数据库最初的模样,HBase 就是 BigTable 的开源实现
- Spanner:虽然已经有了分布式数据库,但是 BigTable 有两个问题:一个是不支持跨行事务,这对于很多高可靠性的业务来说编程会非常困难;另外就是接口模型不是我们熟悉的 SQL,很多应用无法直接使用,因此后面诞生了 Spanner 这个系统,Spanner 可以看成 MySQL 的分布式版本,可以无限水平扩展,能够自动 sharding,并且支持事务,这些特性让传统的应用可以把 Spanner 当做一个无限大的 MySQL 来用。Spanner 是 NewSQL 的旗杆,CockroachDB 和 TiDB 都是模仿 Spanner 而出现的
- CPI:CPI 应该是 Cycles Per Instruction,只是一个衡量应用的运行情况的指标,在 Borg 的论文中提到使用这个参数对应用进行调优
- Dapper:Dapper 是一个分布式系统链路追踪组件,Google 2010 年的一篇论文介绍了它的设计。提出来的 Trace 和 Span 概念已经深入人心,目前开源的 Zipkin 和 Jaeger 都受到了它的影响。从技术深度和含量上来说,Dapper 并不复杂,但是对于越来越复杂的分布式系统的调试来说却非常有用
- Dremel:Dremel 和 Pregel、Caffeine 并称为新时代三驾马车,Dremel 负责实时的交互式查询分析,用户可以使用 SQL 查询 PB 级别的数据,结果能够在秒级别返回。Google 提供的 BigQuery 就是基于 Dremel 的。根据公开数据,Dremel 能够在 10s 级别扫描 350 亿行的数据,性能非常快。Dremel 采用列式存储,以及树形的结构。 Dremel 的缺点是不支持更新操作,因为列式存储会让更新效率非常低。开源社区对标的产品是 Presto
- PowerDrill:和 Dremel 定位类似,也是交互式的查询分析,但是主要定位是分析少量的大数据集,提供更好的分析性能。PowerDrill 数据保存在内存,并且对数据做了分区,因此检索时可以快速跳过不需要的区间。Dremel 和 PowerDrill 对应的开源产品是 Apache Druid
- Percolator:大数据事务处理的解决方案,可以在同一个事务中支持成千上万条数据的更新。Percolator 基于 BigTable,在支持海量数据、随机读写的基础上,加上了对事务的支持。在性能方面,Percolator 偏重于吞吐,在处理时效性方面不是那么好
- Tenzing:SQL on MapReduce 系统,在 MapReduce 系统上面提供 SQL 接口方便用户使用。因为 SQL 是数据分析的标准接口,因此在使用上会比直接编写 MapReduce 代码方便而且兼容性更好。 对标的开源系统是 Apache Hive。
- MillWheel:大规模分布式的流处理系统,随着互联网业务中对实时性的要求越来越高,流处理系统变得越来越重要。MillWheel 的论文在 13 年公开,如今流处理领域在开源已经竞争地如火如荼,Spark 和 Flink 是首选,但是 Storm、Kafka、Pulsar 也是不错的产品
- Pregel:分布式的网络和图算法,可以用于图遍历、最短路径,PageRank 也会用到图算法。对标的开源产品是 Apache Giraph
总结:
Google 的整个架构设计整体采用层级的方式,某些系统成熟稳定之后作为基础,在上层构架其他的服务,比如 BigTable 底层会用到 GFS,很多系统都用到了 Chubby,这种构建方式可以在后期实现快速的新产品开发迭代。
另外能看到的是,Google 内部系统强在对大规模数据的存储、分析和处理,因此在数据库、分布式计算方面的框架非常多,这是为了解决它们实际遇到的问题。这也是 Google 一贯的风格,非常强调实用性,技术非常有前瞻性。
即使是 Google,内部系统的设计也会有大的重构和替代,比如 GFS -> Colossus,Borg -> Omega 等,这是一个大的系统架构演进正常的事情:要么在原来的系统上进行大的重构,要么就是用新的经验重写。而大型系统往往因为代码复杂,设计之初的缺陷改动难度大,上面运行业务迁移和兼容困难,全部重写并不是一个不能接受的选项(尤其是对于 Google 这种有足够技术能力的公司来说)。
Google 在大数据处理方面还是要领先业务不少的,但大家也都知道 Google 开创的大数据领域自己并没有得到什么好处,因此这几年 Google 的模式有了很大的变化:一方面使用 CNCF 和开源来吸引社区用户,一方面把自己的成熟技术直接在 GCE 中做成产品对外开放,把内部技术充分利益化。
对于其他公司来说,没有必要完全复制 Google 的技术栈。架构是演进出来的,公司不同发展阶段应该采用不同的技术架构,另外不同公司遇到的问题和 Google 也会不同,选择适合自己的架构才是正确的路。